
Designing an AI platform isn’t just about picking the best machine learning models; it’s about building a robust, scalable software foundation that can ingest data, train models, and serve predictions reliably. Whether you are building an internal platform for your data scientists or a customer-facing AI product, the software architecture you choose will dictate your system’s agility, cost, and performance.
Let’s break down the primary software architecture options for an AI platform, focusing on structural patterns and when to use them.
1. The Modular Monolith (The Pragmatic Starter)
When launching a new AI initiative, over-engineering is a common trap. The modular monolith keeps all platform components (data ingestion, model training orchestration, and inference APIs) within a single codebase and deployment unit, but strictly divides them into distinct, loosely coupled modules.
How it works: The application runs as a single process. However, internal boundaries are enforced. The UI, API, business logic, and ML pipeline components communicate via internal function calls rather than network requests.
Suitable Design Patterns:
Layered Architecture: Separating concerns into presentation, business rules, and data access layers.
Facade Pattern: Providing a simplified, unified interface to a complex subsystem of ML libraries, shielding the rest of the application from the underlying math.
Pros: Easy to deploy, simpler debugging, lower operational overhead, and no network latency between internal components.
Cons: Harder to scale specific bottlenecks (e.g., if model training requires GPUs but API serving does not, you must scale the whole monolith), and risks turning into a “big ball of mud” if discipline slips.
Best for: Startups, MVP development, or teams with limited DevOps resources.
2. Microservices Architecture (The Industry Standard)
As your AI platform matures, you’ll likely need to decouple your services. A microservices architecture breaks the platform down into independently deployable services organized around business capabilities.
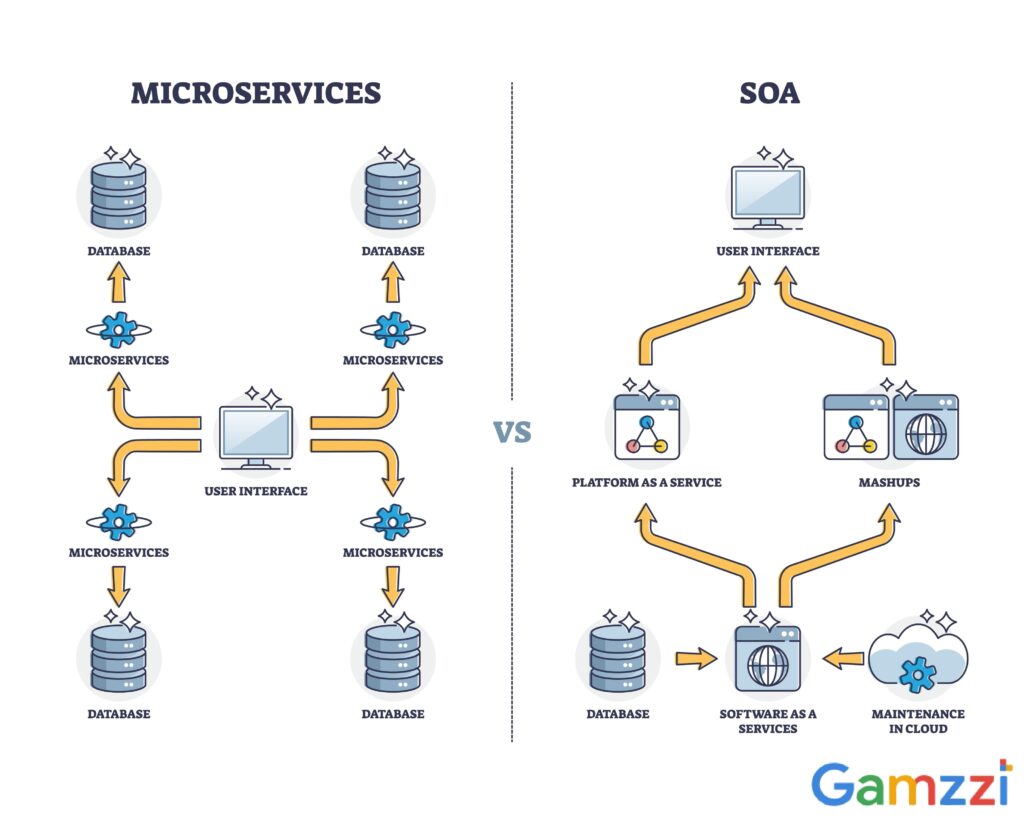
How it works: You might have one service dedicated strictly to data preprocessing, another for managing the Model Registry, and a cluster of services dedicated solely to model inference. These services communicate over the network, typically using REST APIs or gRPC.
Suitable Design Patterns:
API Gateway Pattern: Acts as a single entry point for client requests, routing them to the appropriate inference or data service, and handling cross-cutting concerns like authentication and rate limiting.
Sidecar Pattern: Attaching a helper process to a service (often used for monitoring ML model drift or logging inference requests without cluttering the main application code).
Pros: Highly scalable (you can provision expensive GPU nodes only for the training service), technology agnostic (you can write data pipelines in Python and API gateways in Go), and allows autonomous team workflows.
Cons: High operational complexity, data consistency challenges, and network latency during complex inter-service communication.
Best for: Large engineering teams, enterprise-grade AI platforms, and systems requiring distinct hardware scaling for different tasks.
3. Event-Driven Architecture (The Real-Time Powerhouse)
If your AI platform needs to react to data streams in real time (such as fraud detection, dynamic pricing, or real-time recommendation engines) an event-driven architecture is the way to go.
How it works: State changes or significant events (e.g., “User Clicked Item,” “Transaction Processed”) are published to an event bus or message broker (like Apache Kafka). Subscribing services (like your ML inference service or data ingestion pipeline) listen for these events and react asynchronously.
Suitable Design Patterns:
Publish-Subscribe (Pub/Sub): The foundational pattern where producers broadcast events without knowing who the consumers are.
CQRS (Command Query Responsibility Segregation): Separating the systems that write data (e.g., logging interactions) from the systems that read data (e.g., querying model predictions), optimizing both for high throughput.
Pros: Incredible scalability, extremely loose coupling, and native support for real-time, streaming ML data.
Cons: Difficult to trace end-to-end flows, handling out-of-order events is complex, and debugging requires sophisticated distributed tracing tools.
Best for: Real-time analytics, IoT predictive maintenance, and high-throughput transactional systems.
4. Serverless / Cloud-Native Architecture (The Agile Operator)
For teams that want to focus purely on code and models without managing infrastructure, a serverless architecture leverages managed cloud services to run the platform.
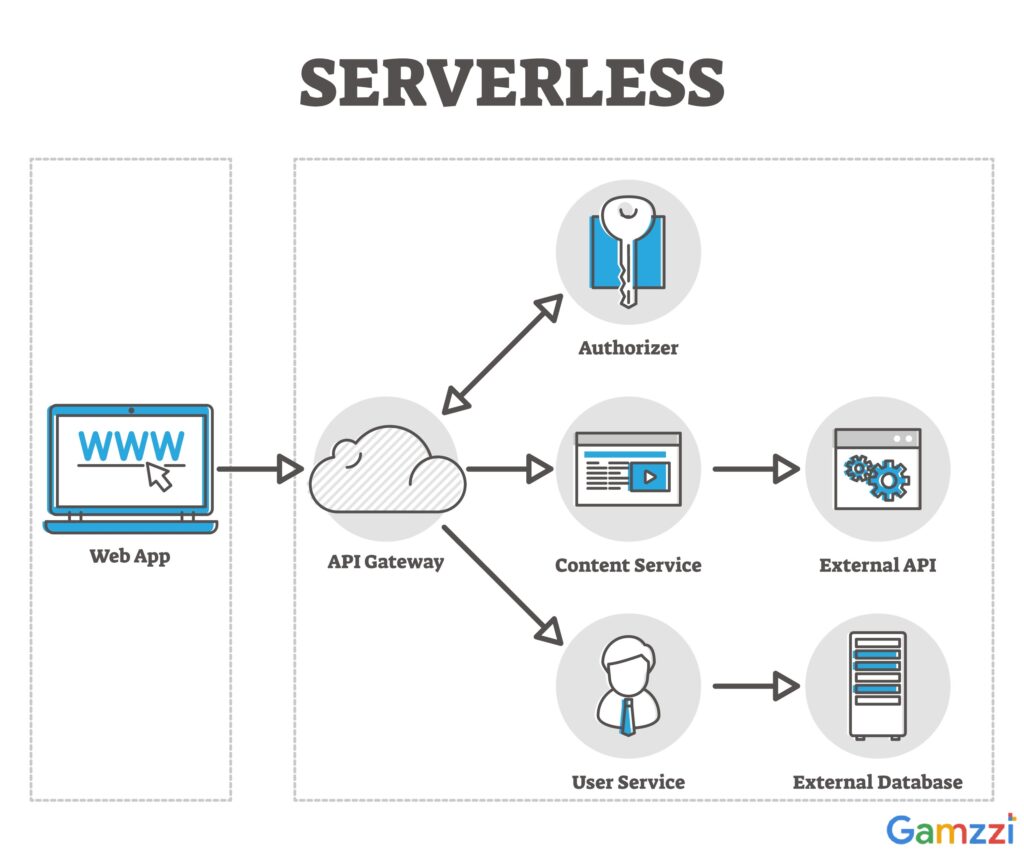
How it works: You deploy code as functions (e.g., AWS Lambda, Google Cloud Functions) and use managed services for orchestration (e.g., AWS Step Functions), data storage, and event routing. For AI, you might use managed inference endpoints (like AWS SageMaker or GCP Vertex AI) integrated directly into your serverless flow.
Suitable Design Patterns:
Function-as-a-Service (FaaS): Breaking down logic into single-purpose functions triggered by HTTP requests or cloud events.
Choreography Pattern: Instead of a central orchestrator dictating the flow, each serverless function emits an event when it finishes, triggering the next function in the ML pipeline.
Pros: True pay-as-you-go pricing (scale to zero), minimal server management, and rapid time-to-market.
Cons: Cold start latency (which can be problematic for heavy ML models if not managed properly), vendor lock-in, and testing locally can be frustrating.
Best for: Spiky workloads, teams wanting to minimize DevOps, and applications where slight latency on cold starts is acceptable.
The Verdict: How to Choose?
There is no single “best” architecture. The right choice is a trade-off between your team’s size, your performance requirements, and your budget. Many successful AI platforms start as a Modular Monolith to establish product-market fit, gradually strangle out components into Microservices as they scale, and introduce Event-Driven patterns specifically for their real-time inference pipelines.
See how we can accelerate your AI journey: 🔗 Gamzzi AI Development Services

